Z-mind — AI-платформа для распределённого запуска и управления ML-задачами
Запускайте модели в Docker, распределяйте нагрузку по GPU/CPU-кластерам, управляйте очередями и масштабируйтесь без простоев.
Запуск любых ML-моделей
В контейнерах Docker
Балансировка задач
Между серверами в реальном времени
Высокая отказоустойчивость
Федеративной архитектуры
Управление через API
И веб-интерфейс
Offline-ready
Работа в изолированной инфраструктуре
Z-mind Dashboard
Веб-интерфейс управления
GPU нагрузка
78%
CPU нагрузка
65%
Кому и зачем
Когда Z-mind нужен уже сейчас
Если у вас есть несколько моделей, растущий поток задач и инфраструктура из разных серверов, ручное управление быстро становится узким местом.
Z-mind убирает хаос: централизует запуск, распределяет вычисления и делает выполнение задач предсказуемым.
Модели запускаются нестабильно
GPU простаивают, а очереди растут
Сложно понять статус и причины ошибок
Долго добавлять новые обработчики
Нужна работа в закрытом контуре без интернета
Возможности
Единая среда запуска, оркестрации и контроля AI-вычислений
Container-first запуск
Модели поставляются в Docker, изоляция зависимостей и воспроизводимость окружений
Распределённое выполнение
Автоматическое распределение задач по GPU/CPU-серверам
Балансировка нагрузки
Приоритизация очередей и минимизация простоев ресурсов
Очереди по моделям
Отдельная очередь RabbitMQ под каждый обработчик
Мониторинг и логи
Статусы, время выполнения, диагностические логи
API + Web UI
Управление задачами из ваших систем и через интерфейс
Быстрое масштабирование
Добавление узлов без остановки сервиса
Offline-ready
Запуск контейнеров без доступа к интернету при подготовленных образах
Хранение результатов
PostgreSQL для задач, метаданных и прозрачной истории
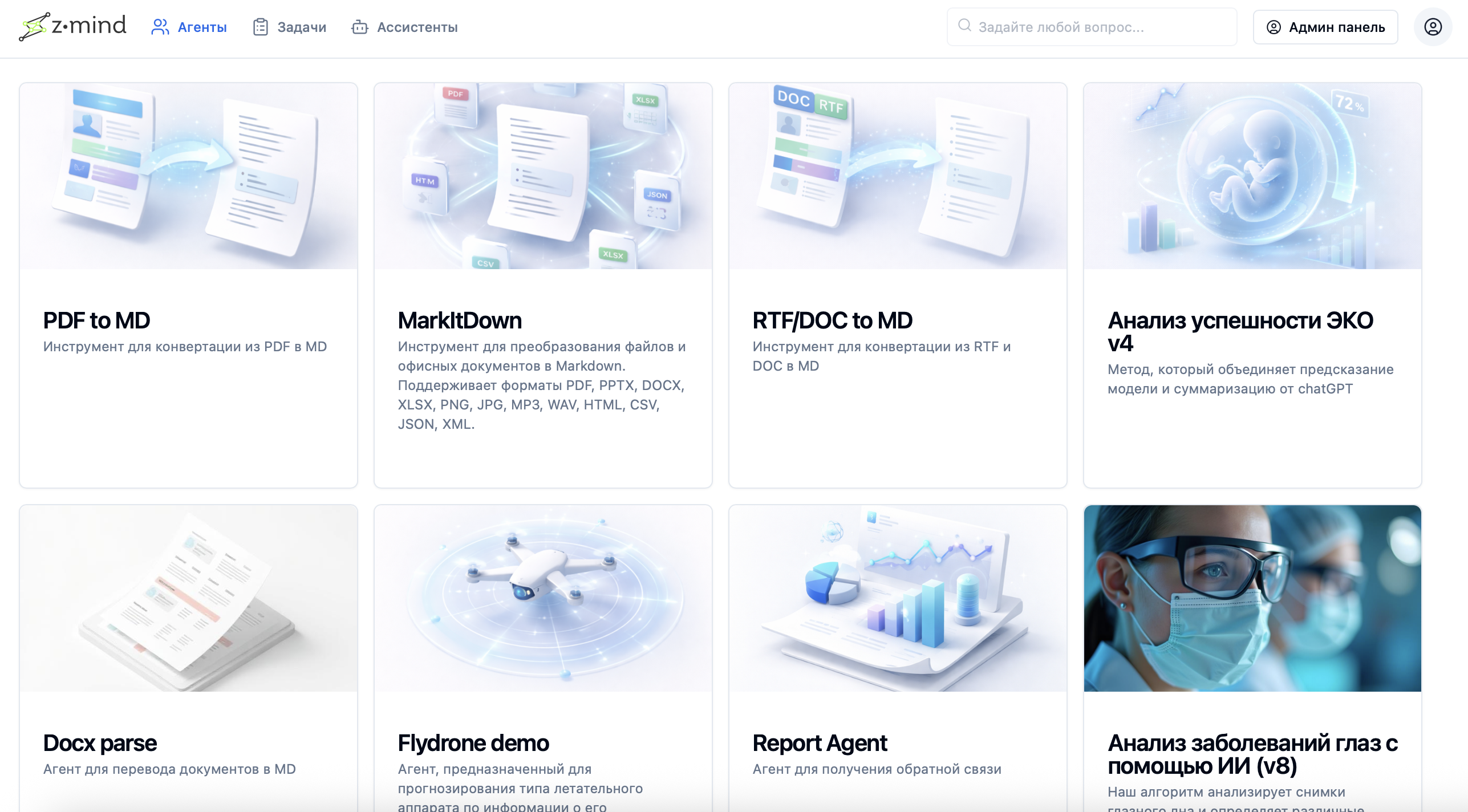
Хостинг сервисов и агентов на распределенной вычислительной инфраструктуре
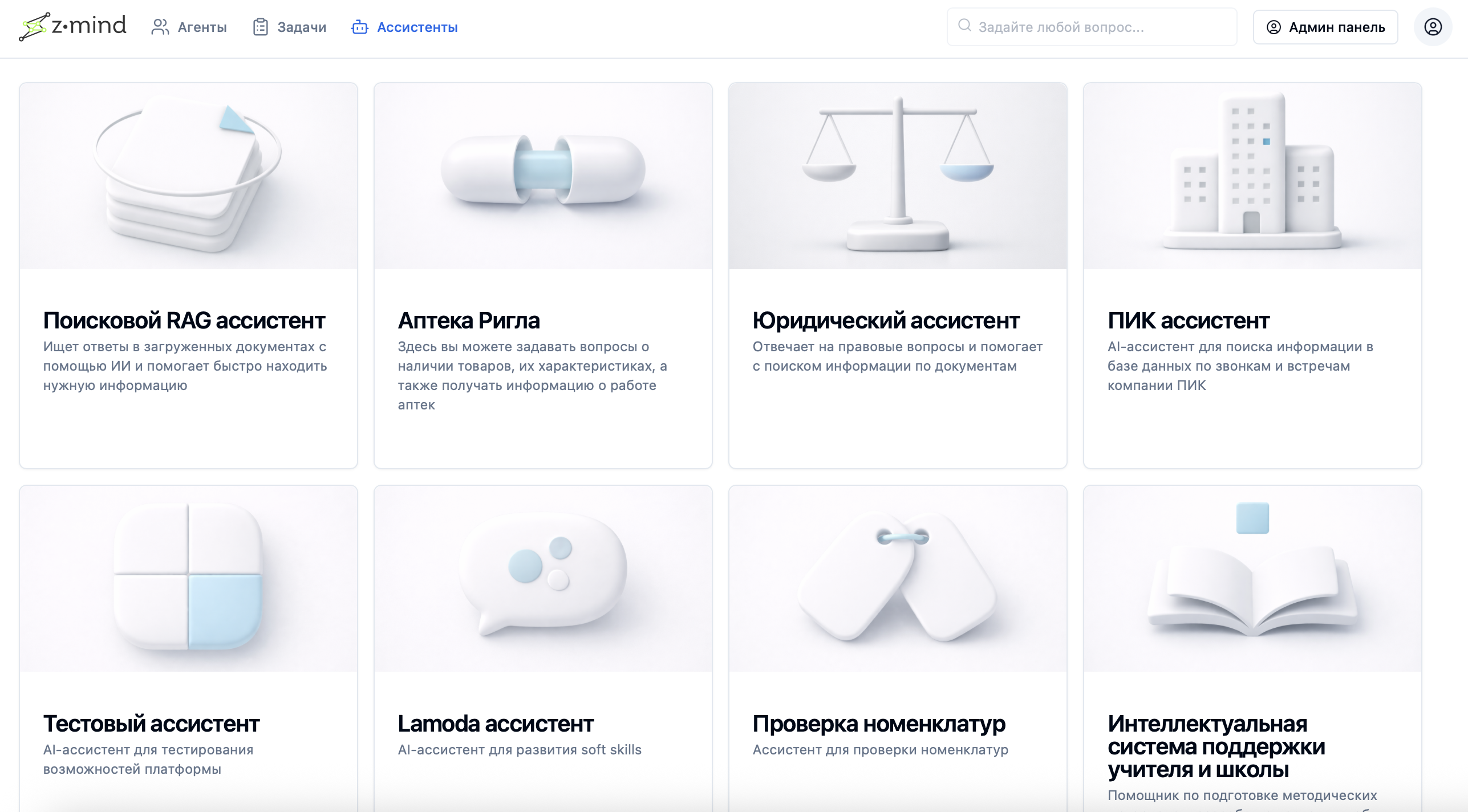
Комбинация агентов и сервисов создает ИИ-ассистентов
Как это работает
Пайплайн обработки задачи в Z-mind
Отправка задачи
Клиент отправляет задачу через API или UI
Очередь модели
Задача попадает в очередь нужной модели (RabbitMQ)
Балансировка
Балансировщик анализирует очереди и загрузку серверов
Выполнение
Pod Script на узле запускает контейнер и выполняет задачу
Сохранение
Результат и метаданные сохраняются в PostgreSQL
Мониторинг
Статус и логи доступны в интерфейсе и API
Схема архитектуры
Архитектура
Федеративная архитектура для стабильной нагрузки и масштабирования
Серверы объединены в федерацию, где каждый узел может запускать контейнеры с нужными обработчиками.
Очереди задач изолированы по моделям, а балансировщик динамически пересчитывает приоритеты с учётом длины очередей, текущей загрузки серверов и количества активных узлов.
API
Node.js
Balancer
Node.js
Pod Script
На вычислительных узлах
RabbitMQ
Очереди
Redis
Приоритеты и быстрые ключи
PostgreSQL
Персистентное хранилище
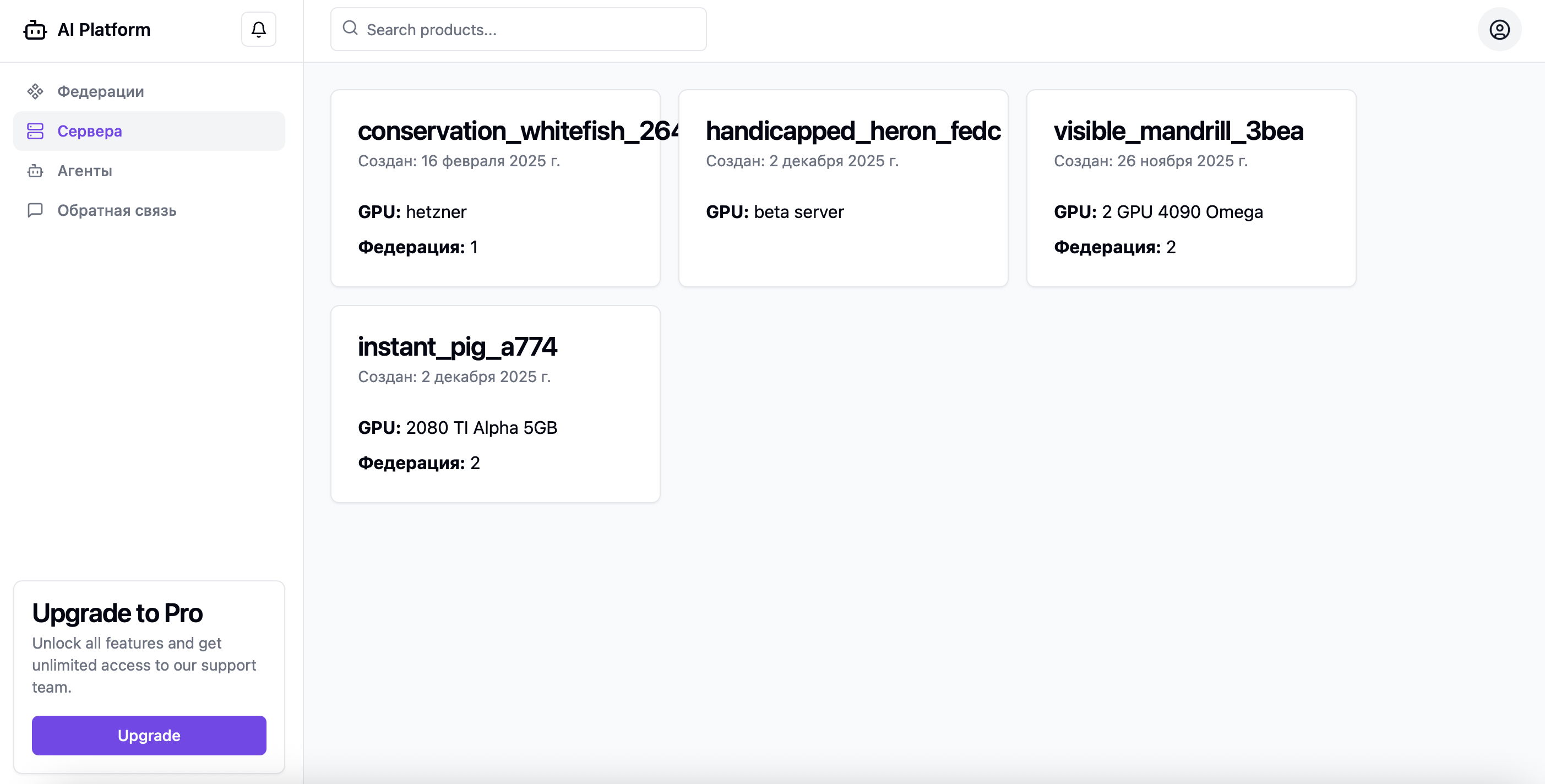
Мониторинг серверов и метрики очередей
Быстрый старт
Новые модели подключаются без перестройки платформы
Собрать Docker-образ модели
Загрузить образ в реестр
Зарегистрировать модель в админке
Начать отправлять задачи в выделенную очередь
Сценарии
Типовые кейсы, где Z-mind даёт быстрый эффект
Массовая обработка документов
Извлечение данных из больших объёмов документов
Пакетный анализ изображений/видео
Обработка медиа нейросетями параллельно
Параллельное тестирование моделей
Сравнение ML-моделей на одних данных
Внутренняя AI-фабрика
Построение централизованной инфраструктуры AI
AI-сервисы в закрытом контуре
Запуск без интернета в защищённой среде
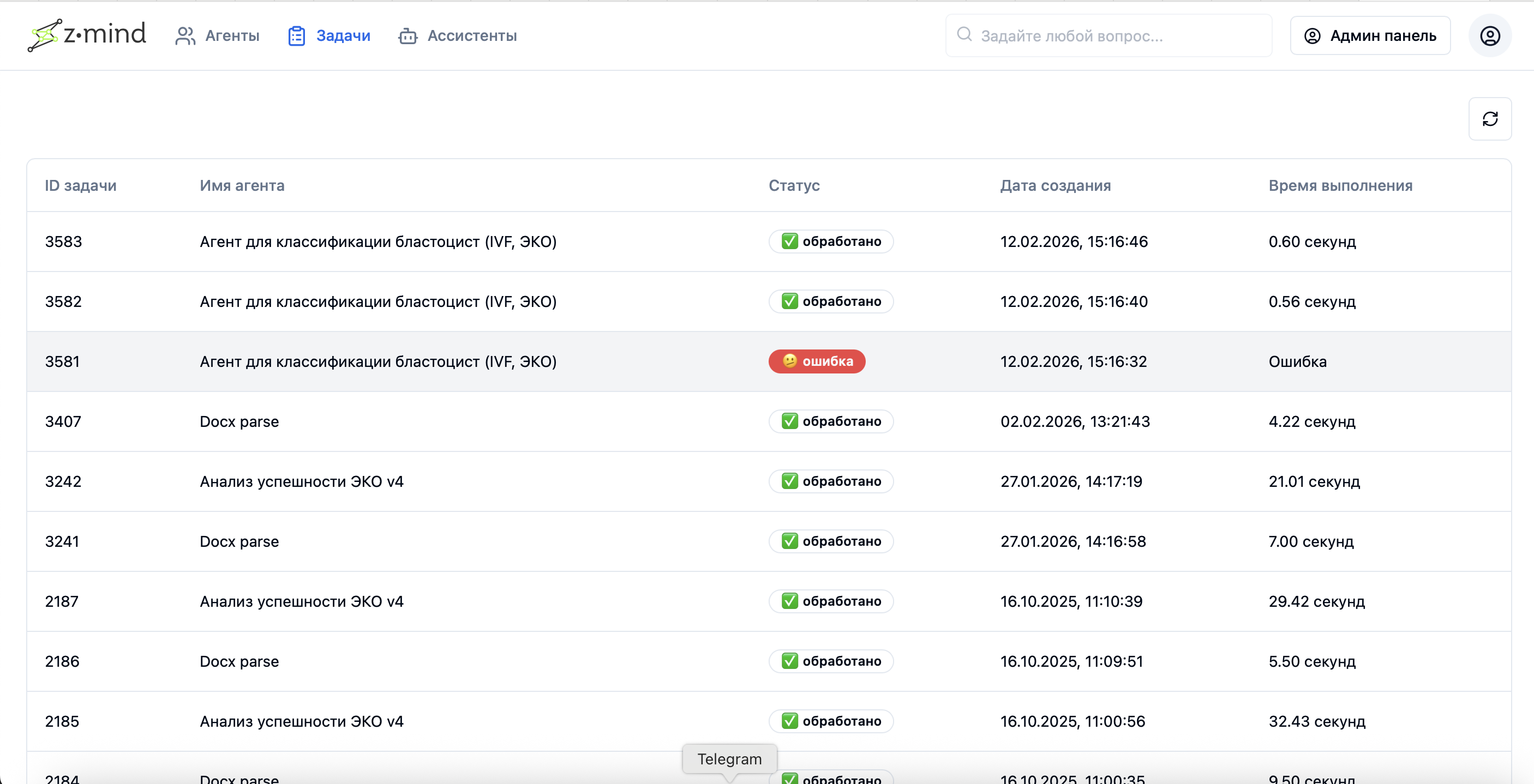
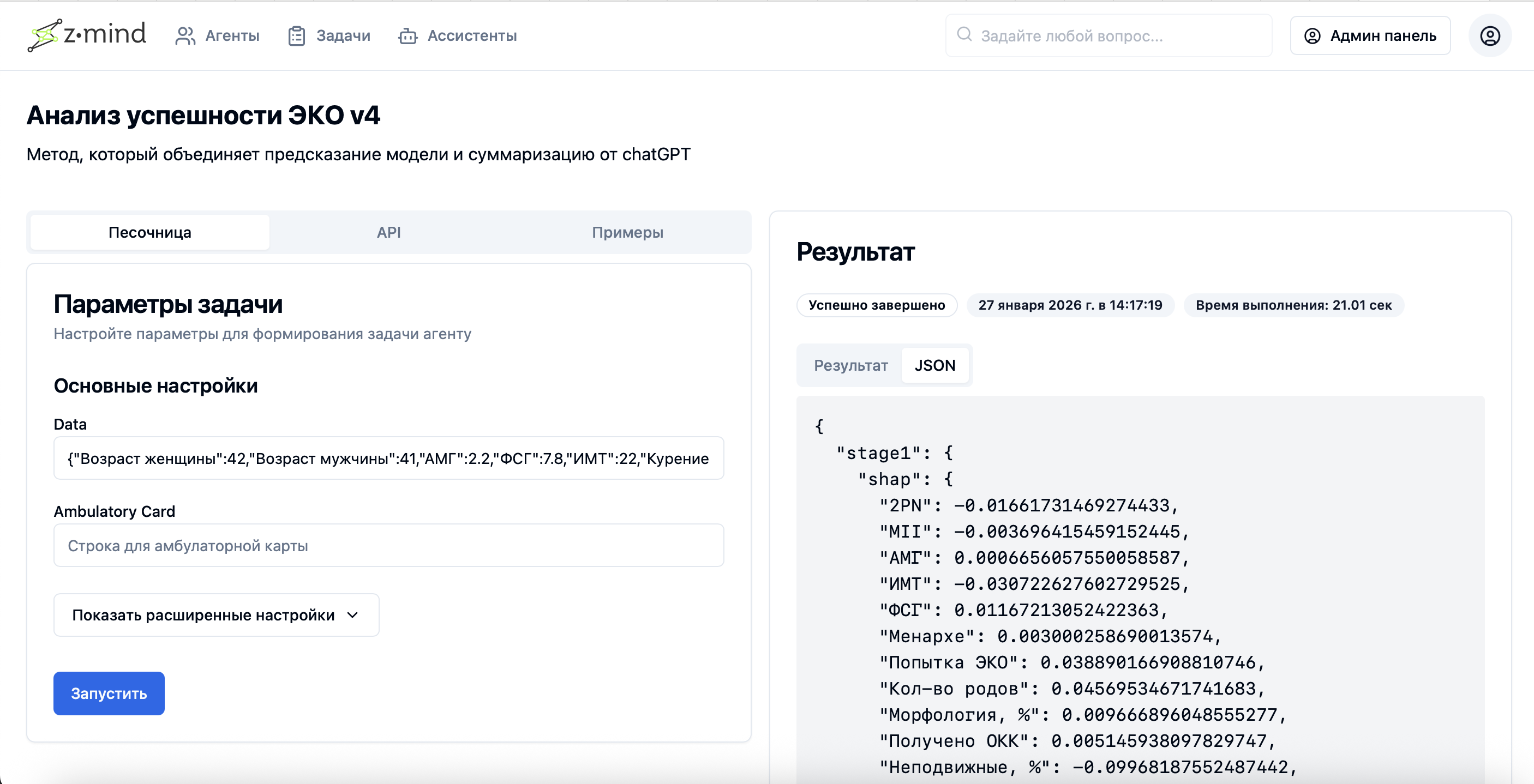
Результат обработки задач сервисов/агентов (результат пакетной обработки)
Пример лога обработки конкретной модели в системе
Интеграция
API-first: подключение к текущим системам без ломки процессов
Z-mind встраивается в существующую инфраструктуру через API.
Вы можете автоматически создавать задачи, получать статусы, собирать результаты и встраивать платформу в текущий ETL/ML/бизнес-процесс.
API пример
/tasksсоздать задачу/tasks/{id}получить статус/tasks/{id}/resultполучить результатНадёжность
Стабильная работа в промышленной эксплуатации
Изоляция задач по очередям
Контроль приоритетов в реальном времени
Централизованные логи и наблюдаемость
Переносимость контейнеров между серверами
Работа в offline-сценариях
Внедрение
Гибкие варианты запуска
Подбираем конфигурацию под объём задач, требования безопасности и SLA.
On-Premise
Установка в контуре заказчика
Private Cloud
Выделенная среда
Гибрид
Часть мощностей локально, часть в облаке
Результаты
Что получает команда после запуска Z-mind
Ускорение обработки задач
до 340%
Снижение простоев узлов
до 85%
Подключение новой модели
с 5 дней до 2 часов
Прозрачность выполнения
100% задач
FAQ
Частые вопросы
Покажем Z-mind на вашем сценарии за короткий пилот
Проведём архитектурную сессию, оценим нагрузку, предложим конфигурацию и запустим пилот с измеримым результатом.